
Tips on ZIPs – Part III: ZIP code Boundaries
WHAT MORE COULD THERE BE TO KNOW ABOUT ZIPS?
We introduced in the last post how ZIP codes were first introduced in the 1960s and how they were developed to help the Postal Service improve nationwide mail distribution. As we also mentioned previously, although ZIP codes were enumerated based on regional sorting facilities, geographic boundaries do not technically exist. ZIPs are actually designations identifying the point of delivery (i.e. a street address or Post Office), rather than any defined bounding region. The best example of this “placeless” designation is the US Navy, which has its own ZIP code, but no permanent location. Similarly, any high-volume recipient can have its own unique ZIP code, such as corporate headquarters, government agencies, or large institutions. ZIP codes that do represent a physical area are typically just mail delivery routes – meaning that you could have a ZIP code within another ZIP code. There are four primary types of ZIP codes: PO Box, Unique, Military, and Standard. PO boxes are located at the post office itself; unique codes refer to individual addresses; US military bases overseas have a domestic mailing address; and standard codes designate everything else (i.e. the “normal” ones). So, ZIP code boundaries can therefore be non-contiguous, undefined, or non-existent. In other words, it is fairly difficult to create a truly representative map, and the maps of ZIP codes that do exist are not comprehensive. Even more problematically, ZIP codes change – but more on that later.
SO, WHAT DOES THIS MEAN FOR DATA MAPPING?
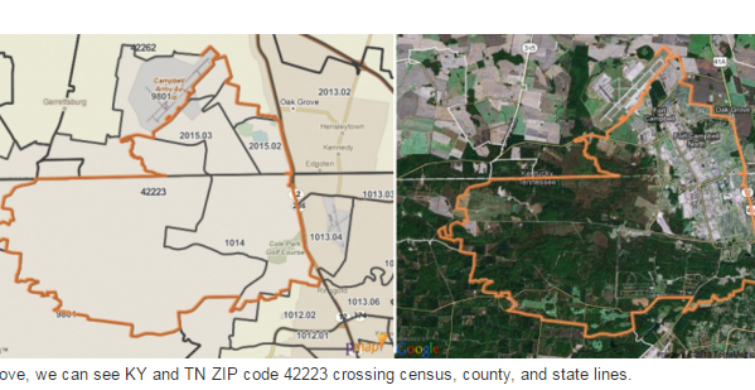
Since ZIP codes are defined to make mail delivery more efficient, there is little consideration for how geographic boundaries might line up with existing political and administrative designations. In some cases ZIP codes cross state, county, and municipal boundaries. And it goes without saying… census tracts and other areal units used for statistical data collection do not reliably match up with ZIP code regions. The Census has created ZIP Code Tabulation Areas (ZCTAs) to provide an “interpolated” representation of ZIP code boundaries in order to supply census data at these “familiar” geographies. The trouble, however, is that while census blocks use streets as edge boundaries, postal delivery routes generally service both sides of a single street. Therefore, census blocks near the edge of ZCTAs are commonly split between ZIP codes. Census ZCTAs assign to each census block the most frequently occurring ZIP code for all addresses contained within the block. These issues make it difficult to match ZIP codes to larger geographies as well (ZIP codes are frequently split between counties).

Above, we can see KY and TN ZIP code 42223 crossing census, county, and state lines.
AND, WHAT DOES POLICYMAP USE?
For GIS services it is often ideal for ZIP code boundaries to be made available – particularly for marketing services and commercial retail, which typically collect data based on customer addresses. At PolicyMap we make a number of data sets available at the ZIP code level. And we’ll be rolling out a whole lot more information at the zip code level in the very near future, due to the utility of the data for our users. A private data provider that contracts with the USPS supplies PolicyMap’s ZIP code boundaries, which are created to match USPS designations (i.e. they are not interpolated in the way that ZCTAs are). These boundaries are polygons generated from the list of deliverable addresses, as provided by USPS, and generally form for the US street/road network. Due to consolidation and frequent changes in the USPS, these boundaries need to be continually updated, and therefore PolicyMap does not often provide change indicators across time periods at the ZIP code level.